Concurrencia estructurada en Java: qué resuelve, cómo se usa y por qué aprenderla ahora
Introducción
Si has trabajado con concurrencia en Java por más de dos años, conoces la sensación. El código se ve simple cuando todo va bien, pero cuando algo falla en producción aparecen dependencias invisibles, hilos huérfanos consumiendo recursos, timeouts que no se propagan, y un thread dump donde no se entiende quién está esperando a quién.
Esta guía explica qué es la concurrencia estructurada, cómo funciona la API actual en JDK 25, y cuándo tiene sentido usarla. Asume que ya sabes qué es un ExecutorService y que en algún momento te has encontrado limpiando el desastre que deja uno cuando algo sale mal.
1. El problema que llevamos arrastrando
El modelo clásico de Java (ExecutorService + Future + CompletableFuture) tiene un defecto de raíz: las relaciones entre tareas son invisibles para el lenguaje y para el runtime. Tú creas un executor en un hilo, otro hilo le envía trabajo, y los hilos que ejecutan ese trabajo no tienen ninguna relación con quien los originó. La especificación oficial de Java lo llama "patrones no restringidos de concurrencia". Es un nombre técnico para algo que en la práctica significa que nadie sabe quién es padre de quién, así que cuando algo se rompe, todos seguimos corriendo.
De esa falta de estructura salen los problemas que probablemente ya conoces.
Los thread leaks son el primero. Si el hilo padre muere o lo interrumpen, los hijos siguen corriendo: siguen pidiendo conexiones de base de datos, consumiendo CPU, ocupando memoria, hasta que terminen lo que estaban haciendo, sin que nadie los espere ya.
Después está la cancelación manual. Si una de las cinco subtareas que disparaste falla, las otras cuatro no se enteran. Para cancelarlas tienes que escribir el código tú mismo, con try/finally, llamadas a future.cancel(true), manejo cuidadoso del estado. Y seamos honestos: ese código casi nadie lo escribe bien a la primera, y casi nadie lo revisa bajo escenarios de fallo.
Y luego está la observabilidad. Un thread dump te muestra una sopa de hilos sin jerarquía visible. No hay forma directa de saber qué subtarea pertenece a qué request. Cuando una API se vuelve lenta a las 3 de la madrugada, te toca adivinar mucho más de lo que deberías.
La concurrencia estructurada parte de la misma intuición que en los años 60 movió a la programación estructurada. Si los goto arbitrarios hacían imposible razonar sobre el flujo de un programa, los hilos sin estructura hacen lo mismo con la concurrencia. La solución es la misma de siempre: imponer bloques con entrada y salida bien definidas.
La regla central es esta: si un bloque de código creó subtareas, ese bloque no puede salir hasta que todas las subtareas hayan terminado, fallado o sido canceladas. El árbol de tareas se refleja en la estructura sintáctica del código, igual que las llamadas a funciones se reflejan en la pila.
2. Estado actual de la API (importante porque está cambiando)
Antes de mostrar código hay que aclarar algo, porque si no vas a confundirte mucho leyendo material de internet. La API ha evolucionado bastante desde su primera aparición:
- JDK 19 (2022): aparece como módulo incubator (JEP 428)
- JDK 21 (2023): primer preview real (JEP 453),
fork()ahora devuelveSubtasken vez deFuture - JDK 22, 23, 24: tres re-previews sin cambios estructurales
- JDK 25 (2025): cambio importante (JEP 505). Los constructores públicos desaparecen y se reemplazan por factory methods estáticos. Aparece la abstracción
Joiner - JDK 26 (2026): sexto preview (JEP 525), refinamientos menores en timeouts
- JDK 27 (esperado finales 2026): finalización prevista
Esto significa que mucho material de YouTube y blogs muestra la API vieja con ShutdownOnFailure y ShutdownOnSuccess. Esos nombres siguen siendo útiles para entender los conceptos, pero el código que vas a escribir hoy usa una sintaxis distinta. Más adelante hay una tabla de traducción.
3. El modelo mental: jerarquía padre-hijo
Piensa en una llamada de función ordinaria. Cuando entras al bloque, tienes una garantía implícita: cuando el bloque termine, todo lo que pasó adentro ya pasó. No hay forma de que una variable local "siga ejecutándose" después del return. La concurrencia estructurada le da esa misma garantía a los hilos.
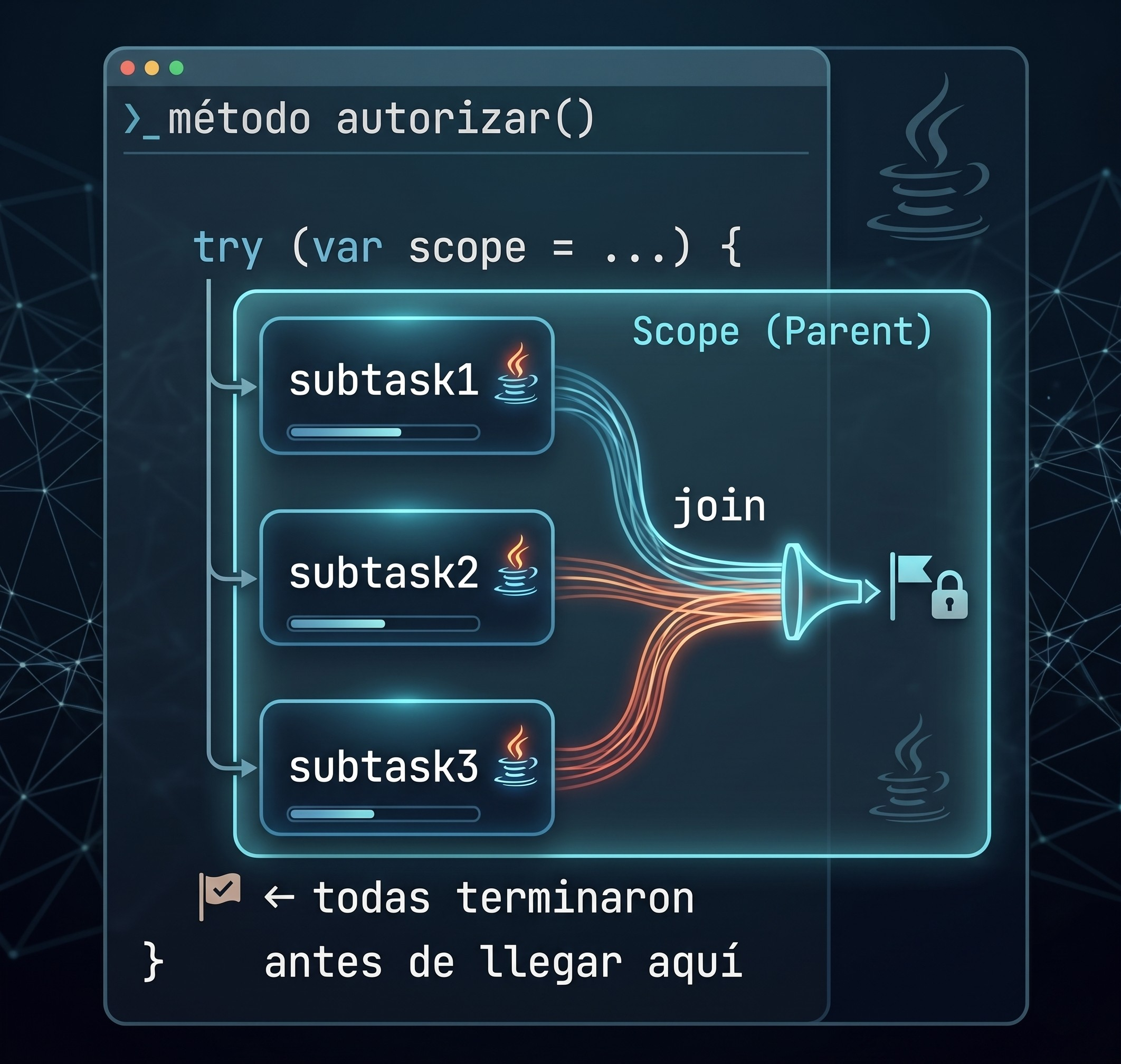
Cuando el try-with-resources cierra el scope, tienes la garantía de que las tres subtareas o terminaron exitosamente, o fallaron, o fueron canceladas. No queda ninguna corriendo a tus espaldas. Y si una subtarea falla, las demás se cancelan automáticamente, sin que tengas que escribir el código tú.
4. Un caso real: autorización de pagos
Imagina que trabajas en una pasarela de pagos. Tienes un endpoint que recibe una solicitud de autorización de transacción. Para autorizarla necesitas hacer tres cosas en paralelo:
- Consultar el saldo del usuario en la billetera
- Llamar al motor antifraude
- Obtener la tasa de cambio actual si la transacción es en moneda extranjera
Las tres son independientes entre sí, las tres bloquean en I/O, y si cualquiera falla no tiene sentido autorizar la transacción.
La versión con CompletableFuture
public AuthorizationResult authorize(PaymentRequest req) {
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
try {
CompletableFuture<Balance> balanceF =
CompletableFuture.supplyAsync(() -> wallet.getBalance(req.userId()), executor);
CompletableFuture<FraudScore> fraudF =
CompletableFuture.supplyAsync(() -> fraud.evaluate(req), executor);
CompletableFuture<ExchangeRate> rateF =
CompletableFuture.supplyAsync(() -> fx.rate(req.currency()), executor);
CompletableFuture.allOf(balanceF, fraudF, rateF).join();
return buildAuthorization(balanceF.get(), fraudF.get(), rateF.get());
} catch (Exception e) {
// ¿Cancelo los otros futures? ¿Cómo? ¿Y si uno falló y los otros siguen?
throw new AuthorizationException(e);
} finally {
executor.shutdown(); // ¿esperar? ¿no esperar? ¿interrumpir?
}
}
Este código compila, pasa los tests del camino feliz, y tiene problemas serios bajo fallos. Si fraud.evaluate() lanza excepción a los 50 milisegundos, las otras dos consultas siguen corriendo hasta terminar. Si el cliente HTTP cierra la conexión y el thread del request es interrumpido, los tres hilos hijos no se enteran. Y si quieres propagar el traceId y el userId para observabilidad, tienes que copiarlos manualmente al ThreadLocal de cada hilo.
La versión con concurrencia estructurada (JDK 25+)
public AuthorizationResult authorize(PaymentRequest req)
throws InterruptedException {
try (var scope = StructuredTaskScope.open()) {
Subtask<Balance> balance = scope.fork(() -> wallet.getBalance(req.userId()));
Subtask<FraudScore> fraud = scope.fork(() -> fraud.evaluate(req));
Subtask<ExchangeRate> rate = scope.fork(() -> fx.rate(req.currency()));
scope.join(); // espera a todas. Si una falla, las otras se cancelan.
return buildAuthorization(balance.get(), fraud.get(), rate.get());
}
}
Mira lo que ya no escribes: no hay try/finally para cancelar futures, no hay executor.shutdown(). Si el thread padre es interrumpido porque el HTTP request hizo timeout, las tres subtareas reciben la interrupción de forma transitiva. Si fraud.evaluate() falla, las otras dos se cancelan inmediatamente. El thread dump muestra un árbol con el padre y sus hijos asociados. La política por defecto de open() es exactamente lo que querías escribir a mano: todas tienen que terminar bien, y si una falla, las demás se cancelan.
5. La regla del timeout: nunca esperes para siempre
Hay una regla que aplica tanto a la concurrencia estructurada como a la vida en general: nunca hagas algo sin un timeout. En el código de arriba usé scope.join() sin parámetros, y eso espera indefinidamente a que las subtareas terminen. En producción eso es una bomba de tiempo.
La forma correcta usa joinUntil con un instante específico:
scope.joinUntil(Instant.now().plusSeconds(2));
Si las subtareas no terminan en dos segundos, lanza TimeoutException y el scope cierra cancelando todo lo que siga vivo. En la versión con Joiner de la API moderna se configura distinto, pero el principio es el mismo: pones un techo y lo respetas.
Este error aparece mucho. Alguien escribe join() durante el desarrollo, los tests pasan porque las subtareas son rápidas, pasa a producción, y meses después una llamada externa se cuelga durante 40 minutos arrastrando con ella un pool de threads y tirando un servicio. Pon el timeout siempre, aunque te parezca innecesario.
6. Las dos políticas más comunes
La concurrencia estructurada distingue entre dos casos típicos. En la API vieja (JDK 21) eran dos clases distintas. En la nueva (JDK 25+) son dos Joiner distintos pasados a open().
Caso 1: todas tienen que terminar bien
Es el caso de la autorización de pago de arriba. Todas las subtareas son necesarias, y si cualquiera falla, abortamos. Es la política por defecto.
// JDK 25+
try (var scope = StructuredTaskScope.open()) { ... }
// JDK 21 (vieja API)
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { ... }
Caso 2: la primera respuesta exitosa gana
Útil cuando hay redundancia. Por ejemplo, consultar tasas de cambio en tres proveedores distintos y quedarse con la que responda primero, cancelando las otras dos. Ahorra latencia y es exactamente para lo que se diseñó la cancelación automática.
// JDK 25+
try (var scope = StructuredTaskScope.open(Joiner.<ExchangeRate>anySuccessfulResultOrThrow())) {
scope.fork(() -> bloomberg.rate(currency));
scope.fork(() -> refinitiv.rate(currency));
scope.fork(() -> internal.rate(currency));
return scope.join(); // devuelve la primera exitosa, las demás se cancelan
}
// JDK 21 (vieja API)
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<ExchangeRate>()) {
scope.fork(() -> bloomberg.rate(currency));
scope.fork(() -> refinitiv.rate(currency));
scope.fork(() -> internal.rate(currency));
scope.join();
return scope.result();
}
Un detalle del segundo caso: si usas la política "primer éxito gana", solo te interesa un resultado. No tiene sentido iterar sobre las subtareas y llamar .get() en cada una. La API te da el resultado del único exitoso directamente.
7. Tabla de traducción entre versiones
Para que cuando leas material viejo no te pierdas:
| API JDK 21 (preview) | API JDK 25+ (preview) |
|---|---|
new ShutdownOnFailure() | StructuredTaskScope.open() |
new ShutdownOnSuccess<T>() | StructuredTaskScope.open(Joiner.anySuccessfulResultOrThrow()) |
scope.throwIfFailed() | ya no se necesita: join() lanza |
scope.result() | retornado por join() vía Joiner |
| Heredar la clase para política custom | Implementar Joiner propio |
8. El trío completo: virtual threads, structured concurrency y scoped values
La concurrencia estructurada no es una feature aislada. Forma parte del Project Loom junto con dos piezas más, y entender cómo se combinan importa porque cada una resuelve un problema distinto.
Los virtual threads (finalizados en JDK 21) atacan el costo de los hilos: pasamos de 1-4 MB por hilo de plataforma a unos 4 KB por hilo virtual. Eso te permite tener millones de hilos vivos sin reventar la memoria, lo cual es la única razón por la que tiene sentido tratar a un hilo como algo barato y desechable. Por defecto, StructuredTaskScope usa virtual threads para las subtareas, así que las dos piezas encajan sin que tengas que pensarlo.
La tercera pieza son los scoped values (finalizados en JDK 25), el reemplazo moderno de ThreadLocal. Cuando un scope crea subtareas, esas subtareas heredan automáticamente los ScopedValue bindings del padre. El traceId y el userId fluyen sin que copies nada manualmente.
private static final ScopedValue<String> TRACE_ID = ScopedValue.newInstance();
private static final ScopedValue<String> USER_ID = ScopedValue.newInstance();
public AuthorizationResult handleRequest(PaymentRequest req) {
return ScopedValue.where(TRACE_ID, UUID.randomUUID().toString())
.where(USER_ID, req.userId())
.call(() -> authorize(req));
// Dentro de authorize() y de TODAS sus subtareas,
// TRACE_ID.get() y USER_ID.get() funcionan sin pasar nada explícitamente.
}
A diferencia de ThreadLocal, los scoped values son inmutables dentro del scope. Una vez los pones, nadie los puede cambiar. Eso suena restrictivo hasta que recuerdas cuántos bugs raros has visto por un ThreadLocal que alguien sobrescribió a la mitad de la cadena.
9. Cuándo no usar concurrencia estructurada
No es la respuesta a todo.
Streaming con back-pressure. Si tienes un flujo continuo de datos que produce y consume a ritmos distintos, sigues necesitando Reactor, RxJava o algo similar. La concurrencia estructurada no incluye canales.
Trabajo de fondo de larga duración. Listeners de Kafka, jobs programados, consumidores que viven mientras viva el proceso: su lifetime no está atado a ningún request. No son tareas estructuradas.
Pipelines compositivos funcionales. Si encadenas .thenApply().thenCompose().exceptionally() para transformar resultados asíncronos, CompletableFuture sigue siendo la herramienta correcta. La concurrencia estructurada coordina fan-out, no compone pipelines.
APIs públicas que devuelven futuros. Si tu librería expone métodos cuyo retorno será compuesto por el caller, sigue devolviendo CompletableFuture. La concurrencia estructurada es para coordinar trabajo dentro de un método, no para exportar trabajo asíncrono entre módulos.
Para todo lo demás —el patrón fan-out / gather / fail-fast, que es la mayoría de lo que hace un backend de microservicios— es la herramienta correcta.
10. Cómo arrancar
Para experimentar hoy necesitas Java 25 o 26 y habilitar las preview features con --enable-preview en compilación y ejecución. Es preview, así que no lo metas en producción todavía. Sirve para aprender y para preparar tu código a la finalización en JDK 27.
Material que vale la pena:
- JEP 505 (JDK 25) en openjdk.org/jeps/505. Es la especificación con la API que va a quedar. Seca pero es la fuente de verdad.
- JEP 506 (Scoped Values, ya final). Léelo en paralelo, son features hermanos.
- Charla de Venkat Subramaniam sobre structured concurrency. La mejor explicación pedagógica disponible. Su forma de construir el modelo padre-hijo con un ejemplo de aeropuertos es lo más cercano a una clase magistral que vas a encontrar.
- "Notes on structured concurrency, or: Go statement considered harmful" de Nathaniel J. Smith. No es Java, es Python (Trio), pero es el ensayo fundacional del concepto. Léelo aunque sea por contexto histórico. Está en vorpus.org.
- El canal Inside Java en YouTube tiene videos cortos del propio equipo de Oracle. Busca "Sip of Java structured concurrency".
Conclusión
La concurrencia estructurada no es un cambio mágico. No vuelve a Java un lenguaje funcional ni reemplaza tu sistema reactivo. Lo que hace, sencillamente, es darle al modelo de hilos algo que llevaba veinte años faltando: una manera de razonar sobre el código concurrente con la misma claridad con la que ya razonamos sobre el código secuencial.
El costo de aprenderla es bajo. Si ya conoces try-with-resources tienes resuelta buena parte del camino. El resto es interiorizar los dos Joiner más comunes y meterte en la cabeza la regla del timeout, que de todas formas te conviene aplicar a casi todo lo que hagas.
Lo que sí me preocupa es ignorarla. Cada release que pasa, los frameworks de los que dependes (Spring Boot, Helidon, Micronaut) integran más estas APIs por debajo. Si nunca te sentaste a entender el modelo, el día que tengas que debuggear un thread leak en producción te vas a encontrar leyendo código de StructuredTaskScope por primera vez bajo presión, y esa es la peor manera posible de aprenderlo.
Si tu trabajo cae en el mundo de los microservicios donde un request hace fan-out a tres o cuatro servicios, y la diferencia entre cancelar bien y cancelar mal es la diferencia entre 100 milisegundos y un timeout de 30 segundos, este modelo va a cambiar la forma en que escribes controllers. Va a hacer el código más legible y bastante menos frágil. Para mí, después de veinte años escribiendo código con ExecutorService, ya era suficiente razón.
📌 Nos vemos en la siguiente entrega.
🔗 Redes sociales
- X (Twitter): @geovannycode
- LinkedIn: Geovanny Mendoza
- Blog: www.geovannycode.com
📚 Referencias
-
JEP 505 – Structured Concurrency (JDK 25)
- 📄 Especificación oficial de la API que va a quedar
- 🔗 https://openjdk.org/jeps/505
-
JEP 506 – Scoped Values (JDK 25, final)
- 📄 Feature hermana; indispensable leerla en paralelo
- 🔗 https://openjdk.org/jeps/506
-
Video: Structured Concurrency in Java
- 🎥 La mejor explicación pedagógica del modelo padre-hijo disponible
- 🔗 https://www.youtube.com/watch?v=m1tLl4DIwhk
-
Video: Project Loom: Modern Scalable Concurrency for the Java Platform
- 🎥 Visión general del proyecto completo (virtual threads + structured concurrency)
- 🔗 https://www.youtube.com/watch?v=K8LMm2JW5Sw&t=2261s
-
Video: Java 21 – Structured Concurrency Preview
- 🎥 Walkthrough con código del equipo de Inside Java
- 🔗 https://www.youtube.com/watch?v=l1lIZUGhHEY&t=18s
-
Ensayo: Notes on structured concurrency, or: Go statement considered harmful — Nathaniel J. Smith
- 📄 El ensayo fundacional del concepto (Python/Trio, pero aplica a cualquier lenguaje)
- 🔗 https://vorpus.org/blog/notes-on-structured-concurrency-or-go-statement-considered-harmful/
Date:
Author:
Geovanny MendozaCategory:
Backend, JavaTag:
Java, Concurrencia, Virtual Threads, Project Loom, Structured Concurrency, JDK 25